



Small Business SEO Services Focused On Your Business Through Proven Campaigns

Get in touch with us! You're only a phone call away from improving your company's online marketing.

Talk through your goals and what we have to offer to get a plan that's right for you!




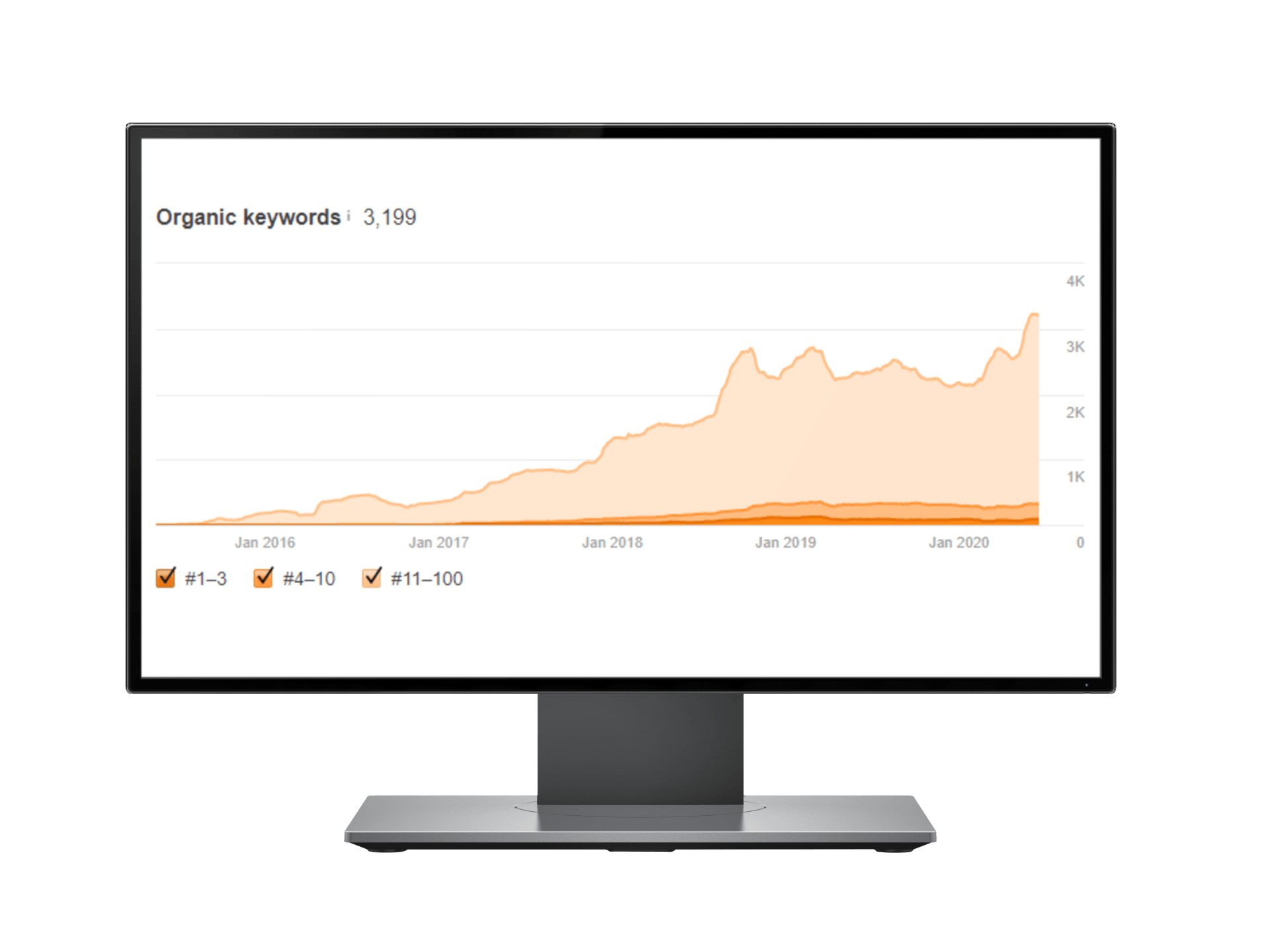
Unlock the Unlimited Potential of Your Business
Our professionals stop at nothing to provide effective SEO for business growth.










FAQs
Got a question? We’re here to help.
















The best small business SEO option available on the market. Small Biz SEO is always one step ahead of Google’s algorithm changes, always keeps us posted on what’s going on and aggressively moving us forward and helping us make important decisions on how to improve our linking, content and technical SEO. Deeply grateful for your guidance, sincerely.
Tim Brown Hook Agency

Small Biz SEO, has been a integral part of our business growth strategy. He has a proven system and monthly metrics to show progress. If your tired of paying overpriced SEO firms with unknown results then I would would highly recommend adding Small Biz SEO to your team. They have shown professionalism incredible customer service and bottom line proven results that I understand and can relate to. 5 Star class act company!

Small Biz SEO hands down has exceeded my expectations for where we are at right now. I had another company for 6 months doing the same thing there is no comparison to where we are now and where we were before. Looking at the numbers we had a goal set for 6 months and surpassed that in 1 month. It's incredible you get what I'm trying to accomplish with my website and business. I'm excited about what the future has for us. I really appreciate it.

Small Biz SEO has done a fantastic job getting our website on the first page on Google for the majority of the target keywords. He provided valuable insights on our website onsite SEO and has been very helpful and knowledgeable about digital marketing. It was a pleasure working with them and we won’t hesitate contracting them again.
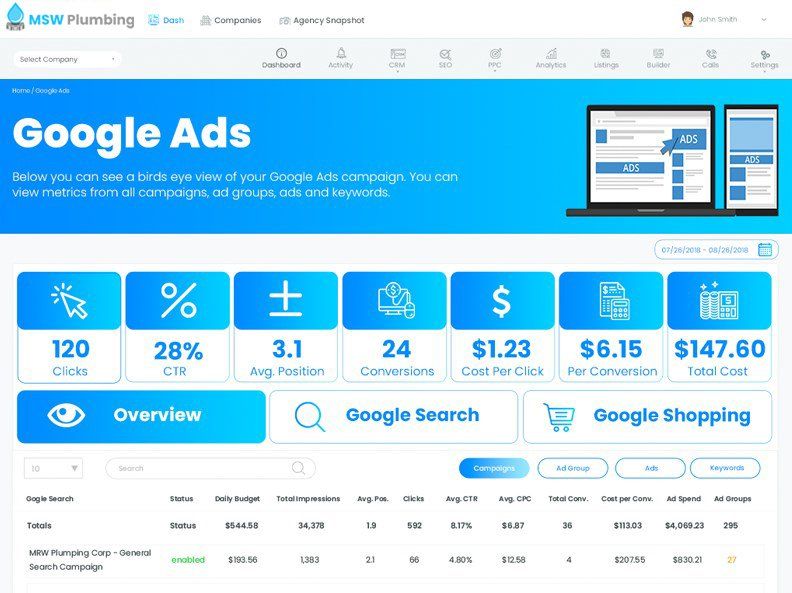
Do you want your business to be found all over online? Small Biz SEO can help. We are a marketing company that specializes in SEO for small business growth. Our team of SEO experts can help you get the most out of your website and increase your online visibility.